Juan Ovalle

AI Engineer | Data Scientist
Technical Skills: Python, SQL, AWS, GCP, Snowflake, Docker
Contact Information
☎️ (+57) 3132593396 | 📧 jj.ovalle@uniandes.edu.co |  https://www.linkedin.com/in/jjmov/
https://www.linkedin.com/in/jjmov/
Education
-
M.S., Data Analytics Intelligence Universidad de los Andes (Aug 2024) -
B.S., Economics Universidad de los Andes (Nov 2020)
Projects
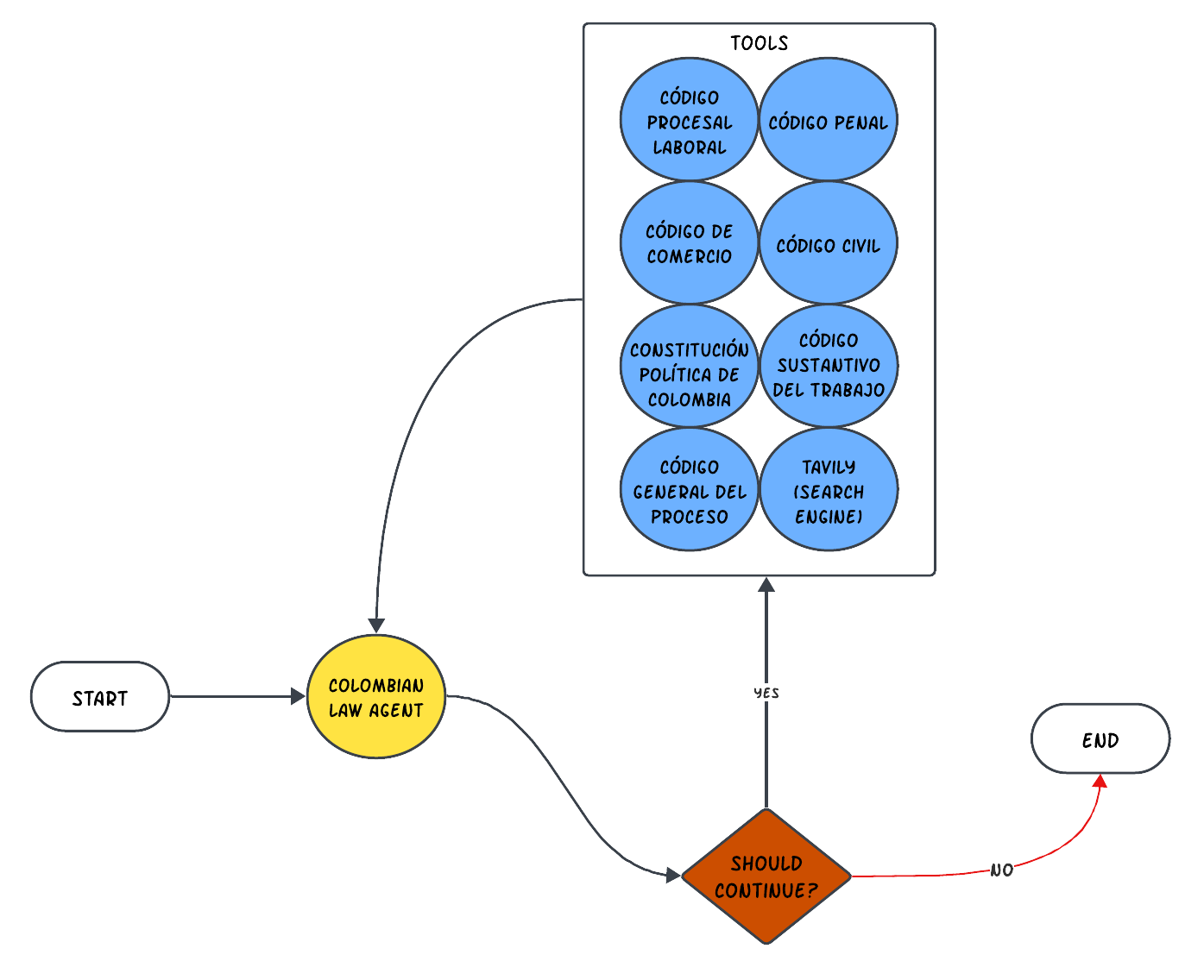
Colombian Law Agent
Relevant Technologies: Qdrant Vector Database, Cohere Reranker, LangChain, LangGraph, Streamlit, Modal
The Colombian Law Agent is an agentic tool designed to simplify the way we interact with legal documents and laws in Colombia. At its core, this project is about making law accessible. Using web scraping techniques, I’ve gathered up-to-date information straight from official sources, because sometimes the latest laws aren’t available in a convenient format.
With the power of vector databases and AI, the Colombian Law Agent can quickly find and retrieve the exact legal information you need. Imagine asking a question about a specific law and getting a precise answer in seconds – that’s what this tool does. It’s built for everyone, from legal professionals to everyday citizens, ensuring that understanding Colombian law is as easy as asking a question. The app isn’t just smart; it’s also user-friendly. A straightforward UI means you don’t need to be a tech wizard to use it. Whether you’re doing in-depth legal research or just curious about a law, the Colombian Law Agent may be your go-to resource, streamlining legal inquiries with technology.
Deploying Mistral7B for Text-to-SQL Tasks
Relevant Technologies: AWS SageMaker, LLamaIndex, LangChain, Streamlit
Deployed Mistral7B into a practical application, leading to the creation of 7BSQL Master. This demo app, developed using AWS SageMaker, LLamaIndex, and Streamlit, showcases the ability to seamlessly transform natural language questions into SQL queries. Hosted on AWS, 7BSQL Master provides an intuitive platform for users to leverage the sophisticated NL2SQL capabilities of Mistral7B, demonstrating the practical application and deployment of fine-tuned AI models in a user-friendly interface.
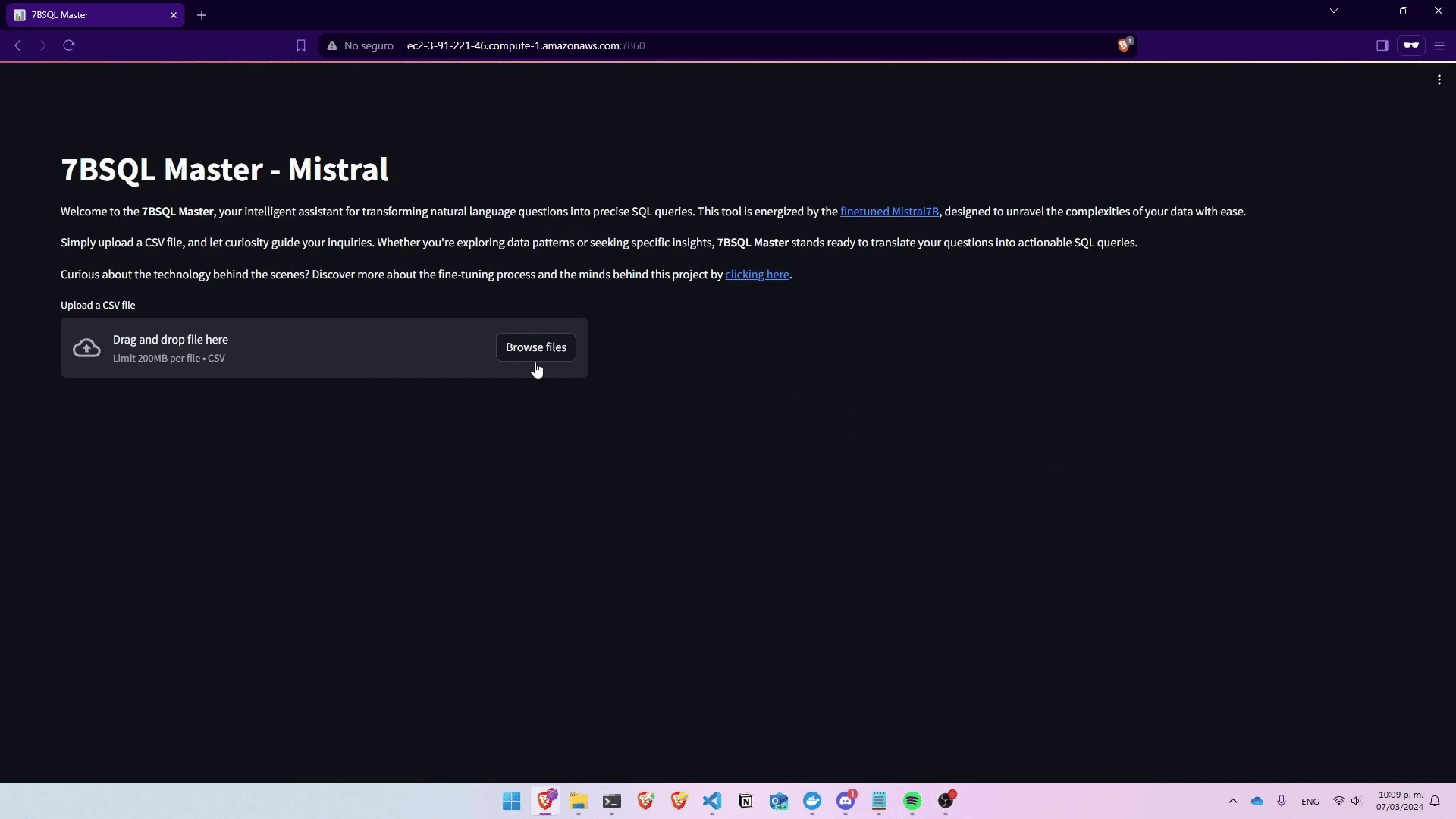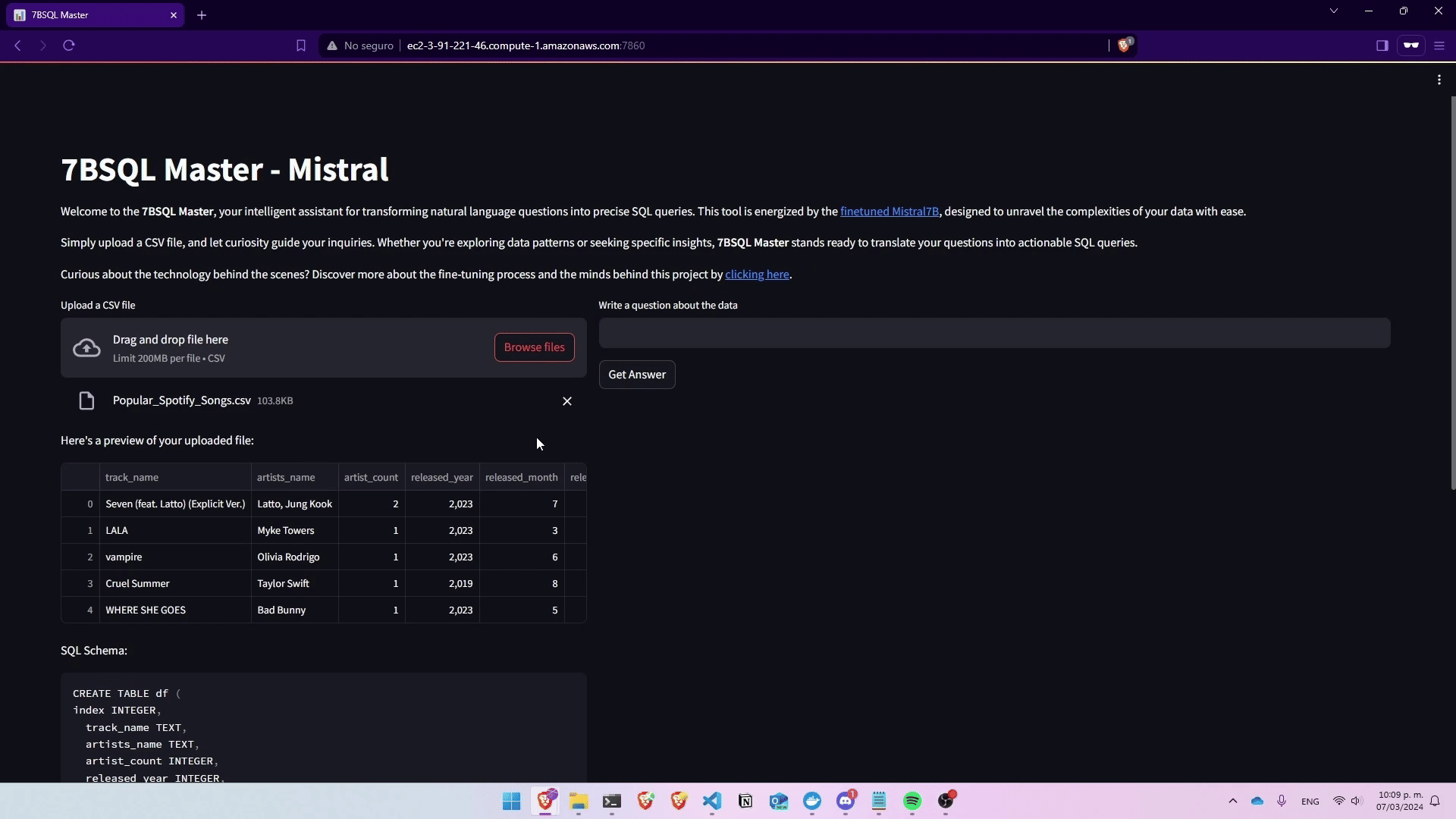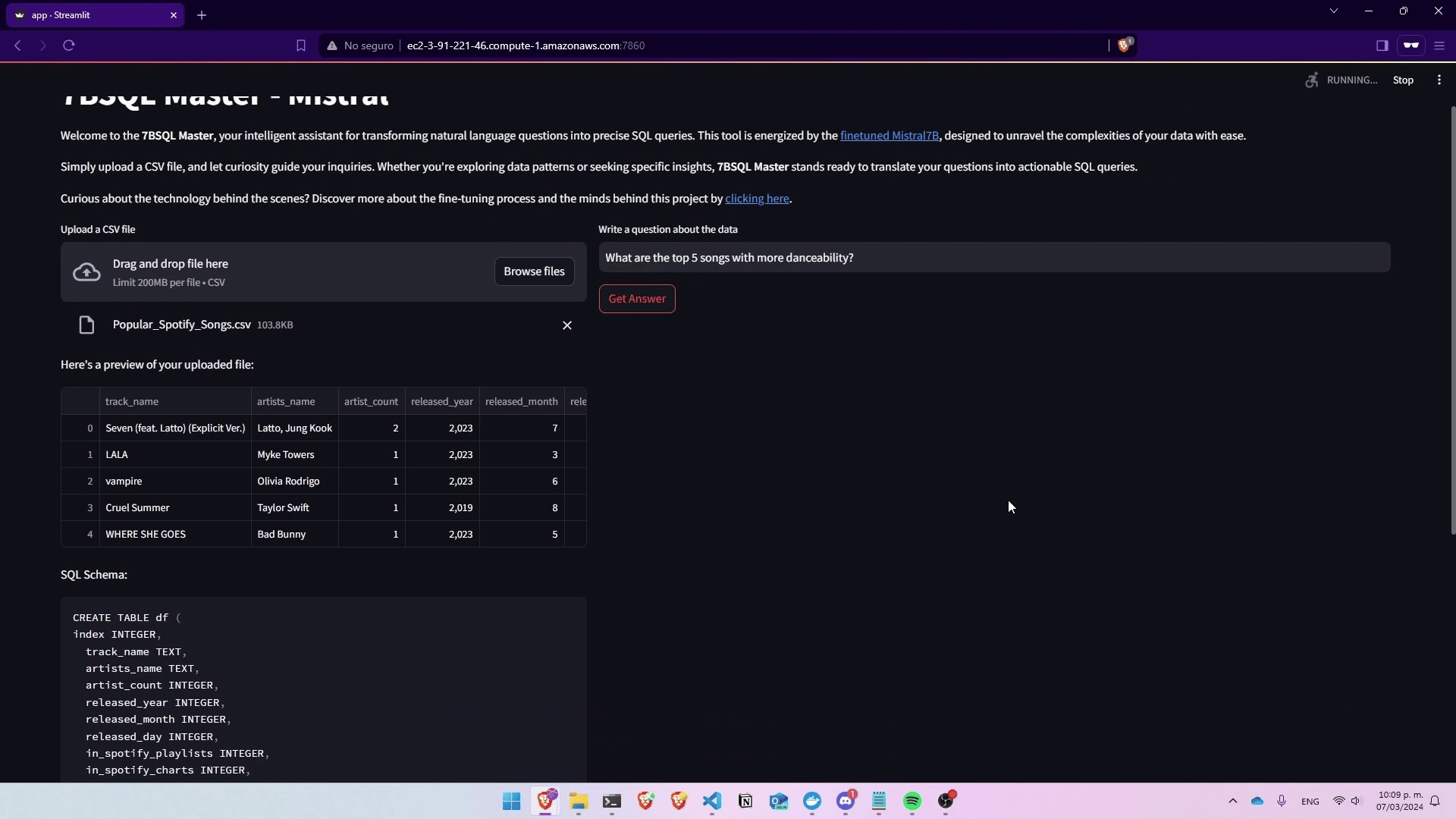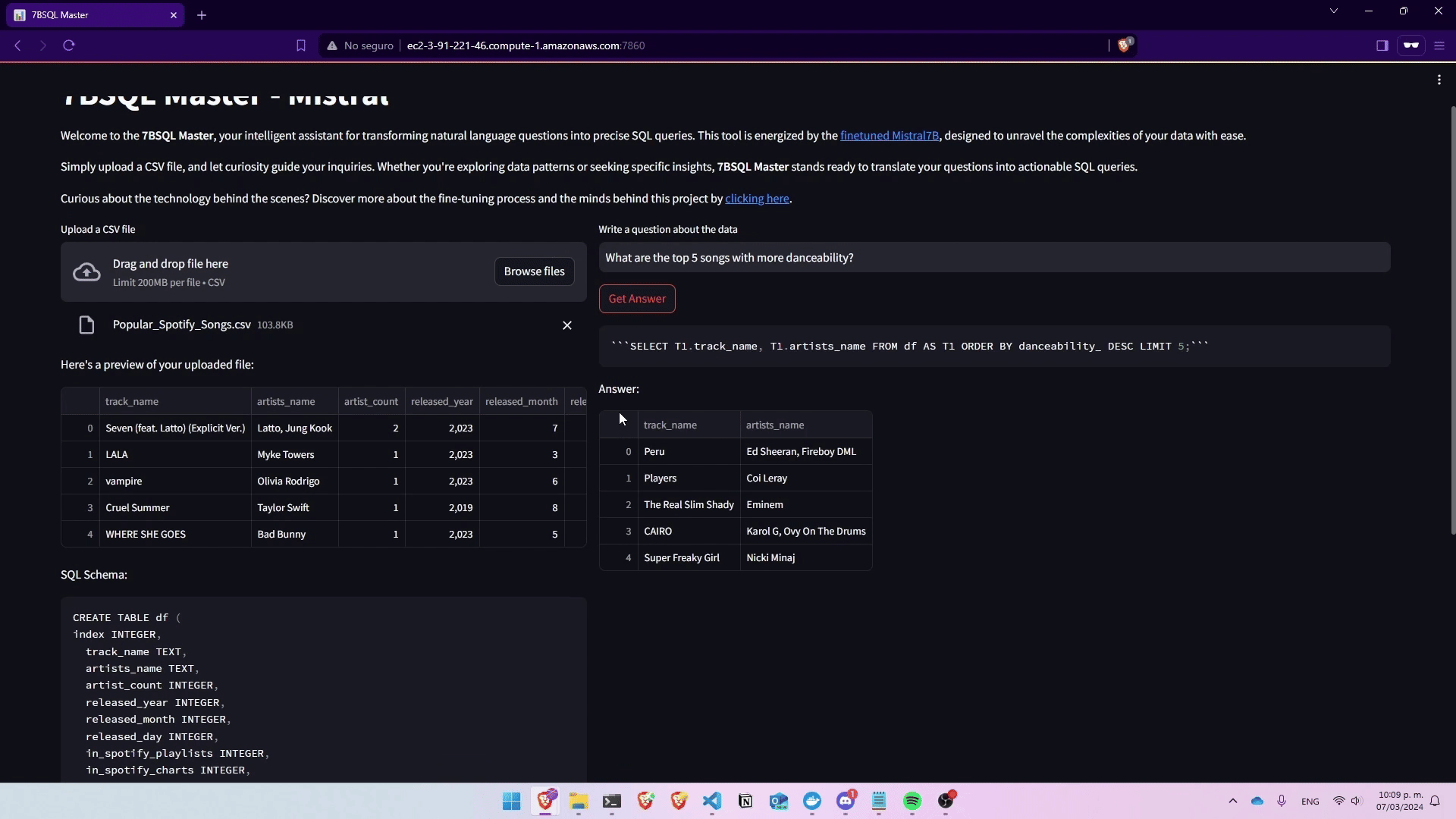
Finetuning Large Language Models for Text-to-SQL Conversion
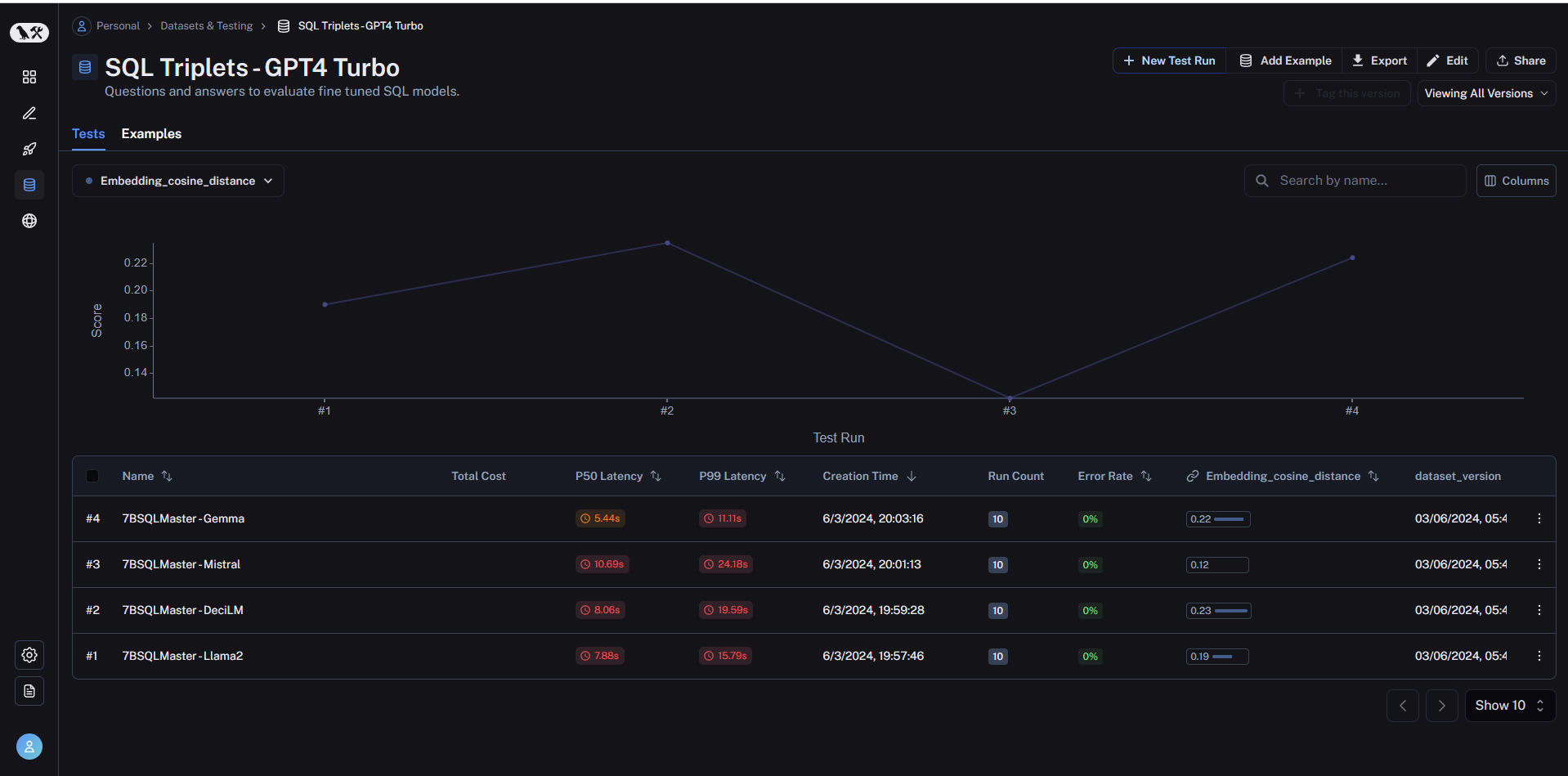
Relevant Technologies: HuggingFace, LangChain, LangSmith, Weights&Biases
Fine-tuned four large language models—Gemma, Mistral, DeciLM, and LLama2, in their 7 billion parameters version, for the task of generating SQL queries from natural language. This project aimed to enable these models to accurately interpret user intent and output corresponding SQL queries. The fine-tuning process employed LoRA (Low-Rank Adaptation) for efficient model parameter tuning. Performance monitoring and evaluation were facilitated by Weights & Biases and LangSmith.
Deploying a Retrieval-Augmented Generation Application
Relevant Technologies: LangChain, Pinecone, Weights&Biases, Chainlit
Developed a Retrieval-Augmented Generation (RAG) application that enables users to interact with PDFs and text files, facilitating conversational ‘chatting’ with documents. This application leverages Pinecone for its vector storage capabilities, ensuring efficient information retrieval that significantly enhances user experience. The app’s workflow is orchestrated using LangChain, allowing for seamless integration of various AI components. To ensure continuous improvement and a deeper understanding of user interactions, Weights and Biases was employed for the tracking of model interactions and performance metrics. The user interface, crafted with Chainlit, provides an intuitive and easy environment for users to effortlessly navigate and converse with their documents

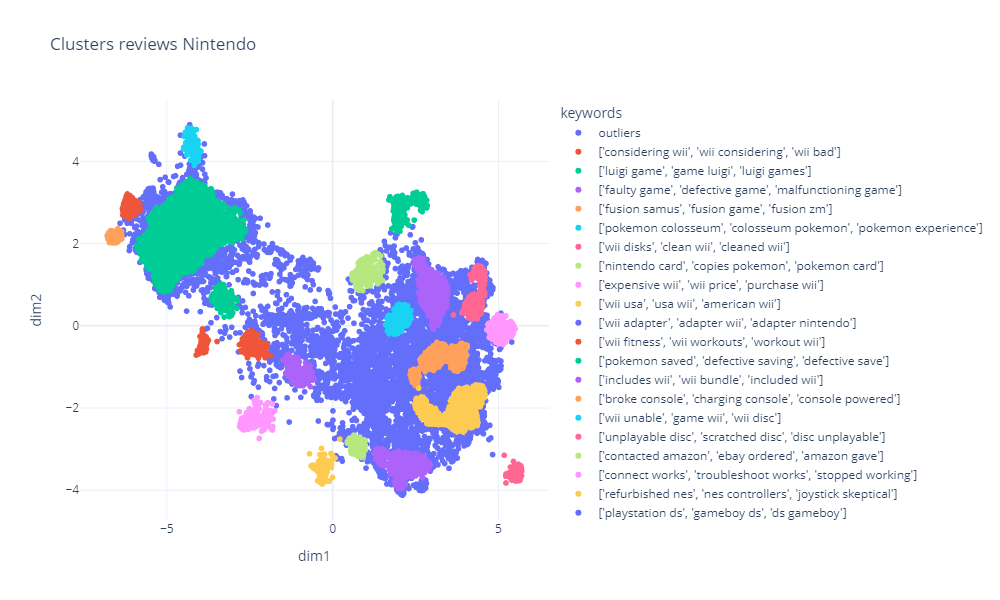
Extracting Business Insights from Amazon Reviews Using NLP
Relevant Technologies: HuggingFace, BigQuery, HDBSCAN, UMAP
Developed a comprehensive NLP project focused on extracting actionable business insights from Amazon reviews of video games. Initially, the sentiment of each review was analyzed to identify negative feedback, utilizing a BERT based model. Following this, an embedding model was applied to transform the reviews into embeddings, facilitating the nuanced understanding of customer opinions beyond mere positive or negative sentiment. Leveraging UMAP for dimensionality reduction and HDBSCAN for clustering, the project effectively grouped reviews into distinct clusters, enabling a focused analysis on specific aspects of customer dissatisfaction.
Work Experience
Senior Data Scientist @ Escala24x7 (October 2023 - Present)
- Developed a Proof of Concept (POC) for Allianz Argentina, utilizing XGBoost in AWS SageMaker to create a predictive model for estimating the number of insurance theft claims
- Implemented an unsupervised machine learning solution on AWS SageMaker to identify high-risk customers, enhancing the efficiency and accuracy of risk assessment
- Led office hours for the Diners Ecuador team, overseeing the Proof of Concept for migrating their machine learning models to the AWS cloud, facilitating a seamless integration and enhancing the team’s cloud competencies
Mid Data Scientist @ Habi (July 2023 - October 2023)
- Designed a prioritization algorithm for Habicredit that streamlined credit legalization, resulting in a 15 working-day reduction in average legalization time. Swiftly adopted across multiple departments
- Created a predictive model for the “Bolsa” phase to gauge credit conversion likelihood, which was integral in shaping conversion-based prioritization strategies
Data Scientist @ Interpublic Group (IPG) – Kinesso (March 2021 - April 2022)
- During my tenure, I advanced to the position of Senior Data Analyst and subsequently assumed a dual role as a Data Scientist. My technical proficiency was recognized, and I was ultimately promoted to a full-time Data Scientist position
- Collaborated on the construction of Math Engine application leveraging AWS services to train models in a more efficient way and removing common bottlenecks
- Participated in different pitches for LATAM market for clients like Coca-Cola and Subway (Lookalike modelling)
- Learned basic management of teams
- Successfully performed shadowing processes for new analyst employees
- Trained both supervised and non-supervised models to successfully locate high value audiences for clients like BMW, CVS, ALDI, among others
- Automatized various process at the company resulting in time-saving tools for other analysts
- Became one of the global points of reference inside the company in technical skills for audience work
Data Analyst @ AXA Colpatria (August 2020 - March 2021)
- Restructured different sources of relevant information stored in various vulnerable Excel files
- Produced dashboards from scratch that were rapidly adopted by other analysts to monitor daily tasks of the company
- Collaborated in the reduction of the average cost of the company in 2020 through the selection of the most cost-efficient prepaid medicine services suppliers